
GPU-Manager说明
组件介绍
GPU Manager提供一个All-in-One的GPU管理器, 基于Kubernets Device Plugin插件系统实现, 该管理器提供了分配并共享GPU, GPU指标查询, 容器运行前的GPU相关设备准备等功能, 支持用户在Kubernetes集群中使用GPU设备。
管理器包含如下功能:
拓扑分配:提供基于GPU拓扑分配功能, 当用户分配超过1张GPU卡的的应用, 可以选择拓扑连接最快的方式分配GPU设备
GPU共享:允许用户提交小于1张卡资源的的任务, 并提供QoS保证
应用GPU指标的查询:用户可以访问主机的端口(默认为5678)的/metrics路径,可以为Prometheus提供GPU指标的收集功能, /usage路径可以提供可读性的容器状况查询
部署在集群内kubernetes对象
在集群内部署GPU-Manager Add-on , 将在集群内部署以下kubernetes对象
kubernetes对象名称
类型
建议预留资源
所属Namespaces
gpu-manager-daemonset
DaemonSet
每节点1核CPU, 1Gi内存
kube-system
gpu-quota-admission
Deployment
1核CPU, 1Gi内存
kube-system
GPU-Manager使用场景
在Kubernetes集群中运行GPU应用时, 可以解决AI训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
GPU-Manager限制条件
该组件基于Kubernetes DevicePlugin实现, 只能运行在支持DevicePlugin的TKE的1.10kubernetes版本之上。
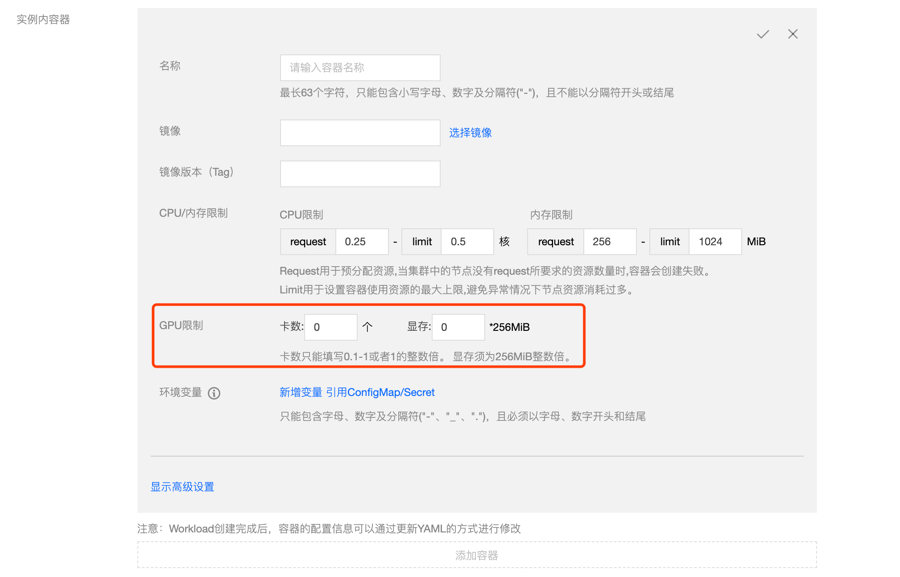
每张GPU卡一共有100个单位的资源, 仅支持0-1的小数卡,以及1的倍数的整数卡设置. 显存资源是以256MiB为最小的一个单位的分配显存。
使用GPU-Manager 要求集群内包含GPU机型节点。
GPU-Manager使用方法
安装GPU-Manager扩展组件
在安装了GPU-Manager扩展组件的集群中,创建工作负载。
创建工作负载设置GPU限制,如图:
yaml创建
如果使用yaml创建工作负载,提交的时候需要在yaml为容器设置GPU的的使用资源, 核资源需要在resource上填写tencent.com/vcuda-core, 显存资源需要在resource上填写tencent.com/vcuda-memory,
使用1张卡
使用0.3张卡, 5GiB显存的应用(20*256MB)
最后更新于